partition by关键字是分析性函数的一部分,它和聚合函数不同的地方在于它能返回一个分组中的多条记录,而聚合函数一般只有一条反映统计值的记录,partition by用于给结果集分组,如果没有指定那么它把整个结果集作为一个分组。
分区函数一般与排名函数一起使用,这里以ROW_NUMBER()和RANK()为例作演示。
我这里先给出全部的SQL语句。
create table Students --学生成绩表 ( id int, --主键 Grade int, --班级 Score int --分数 ) insert Students select 1,1,88 union all select 2,1,66 union all select 3,1,75 union all select 4,2,30 union all select 5,2,70 union all select 6,2,80 union all select 7,2,60 union all select 8,3,90 union all select 9,3,70 union all select 10,3,80 union all select 11,1,75 select *,ROW_NUMBER() over(order by Score desc) as Sequence from Students select *,ROW_NUMBER() over(partition by Grade order by Score desc) as Sequence from Students select *,RANK() over(order by Score desc) as Sequence from Students select *,RANK() over(partition by Grade order by Score desc) as Sequence from Students drop table Students
下面细说各语句。
我们先看看第一个查询语句:
select *,ROW_NUMBER() over(order by Score desc) as Sequence from Students
执行结果如下: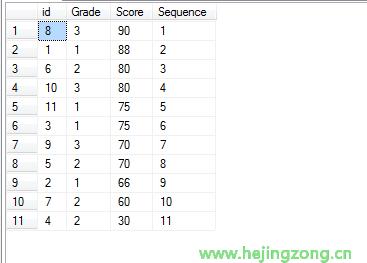
这就是我们常用的显示序号的语句。
再来看看第二个查询语句:
select *,ROW_NUMBER() over(partition by Grade order by Score desc) as Sequence from Students
执行结果如下: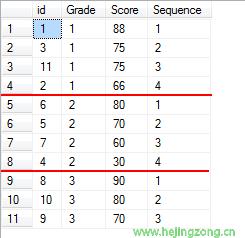
在这里我们用partition对班级进行了分区。也就是按照班级进行排名。
接下来看一下第三个查询语句:
select *,RANK() over(order by Score desc) as Sequence from Students
执行结果如下:
该语句是对分数相同的记录进行了同一排名,如两个80分的并列第三,第四名就没有了,两个75分的并列第五……
最后来看看第四个查询语句:
select *,RANK() over(partition by Grade order by Score desc) as Sequence from Students
执行结果如下:
这个结果相信很多人都预料到了,就是按班级来进行分区,班级内再进行排名。
还有其他一些排名函数请百度:
Dense_Rank():
“Dense_Rank() Over()”返回结果集分区中行的排名,在排名中没有任何间断。
“Dense_Rank() Over()”与“Rank() Over()”用法相同,“Dense_Rank() Over()”只是分组内排名没有间断。
Ntile():
ntile函数可以对序号进行分组处理。这就相当于将查询出来的记录集放到指定长度的数组中,每一个数组元素存放一定数量的记录。ntile函数为每条记录生成的序号就是这条记录所有的数组元素的索引(从1开始)。也可以将每一个分配记录的数组元素称为“桶”。ntile函数有一个参数,用来指定桶数。